Using the saga design pattern in microservice architecture
Šarūnas Norkus
November 18, 2021
Microservices are a great way to scale and maintain applications easily. However, they have their pros and cons. It’s straightforward to start creating a new application like a microservice until we encounter data consistency problems when making requests between microservices.


In monolith applications, we usually use database transactions with ACID (Atomicity, Consistency, Isolation, Durability) properties. In the event of a rollback, it’s easy to ensure data consistency out of the box. But now that our database transactions are spread across multiple microservices, how do we ensure data consistency between them?
One solution is the saga pattern - an older architectural concept that is still highly relevant for microservices today. Saga patterns show promise for our systems, so I’d like to share some of our key insights as we’ve been exploring the use of sagas in our own microservices.
The saga pattern
The saga is a sequence of local transactions in each of the participating microservices. It has its own steps that have to be executed, and when each one is completed, there is some sort of logic to decide what to do next.
The saga must guarantee that all the steps are executed successfully, or else it must perform a rollback if necessary.
The image below illustrates the requests flow between microservices to fulfill a "create order" saga.

Infrastructure or business logic rule exceptions may arise when making requests. All those exceptions should be handled, and if we have an exception in a particular step, we also have to undo all the changes from previous steps.
Sometimes, to do a full rollback, we have to make additional requests to the microservices. These additional requests are known as compensation transactions.
All of this means that using sagas can increase complexity. Because we implement the rollback mechanisms ourselves, each scenario should be carefully considered.
Two ways to implement sagas
There are two ways to implement saga patterns, each of which has a different approach to coordinate the workflow.
Orchestration (centralized): One central coordinator is responsible for calling remote services to fulfill the saga;
Choreography (distributed): There is no central coordinator, so each service should listen and produce events and make decisions on what actions need to be done.
Let's take a deeper look at those implementation methods.
1. Orchestration
The orchestration method is when we have a centralized coordinator that manages all the logic and knows when to communicate with other microservices and what step to do next or how to rollback.

The orchestration method works best when the logic of the saga is maintained by one or two teams. Otherwise, the code could become complicated without anyone responsible for code quality and maintenance.
On the other hand, the orchestration method is better for understanding more complex workflows. This is also a cleaner method from an architectural perspective, since the microservices are not coupled to each other.
Rollback in orchestration
The coordinator should know how to rollback in case of failure. For this reason, the coordinator has to store a log of events for each flow and perform compensation transactions in each corresponding microservices when doing a rollback.
If any failures occur in any of the requests, the event log helps the coordinator identify which microservices are impacted and in which sequence the compensation transactions should be sent.

As you can see in the image above, the payment processing request has failed, the order was rejected and payment was refunded. We also skipped sending an invoice to the client. Alternatively, an invoice could be sent with the information that payment was failed.
This diagram is just an example. In reality, there are a few improvements that could be made to this process, but this example makes the process easier to understand.
2. Choreography
This type of saga is event-based/asynchronous and is implemented when code running in each service decides how to handle events within its scope and what to do next.
You can also think of it as a chain of microservices related to events. Each service listens to others events and publishes its own, but unfortunately it leads to coupling to each other.
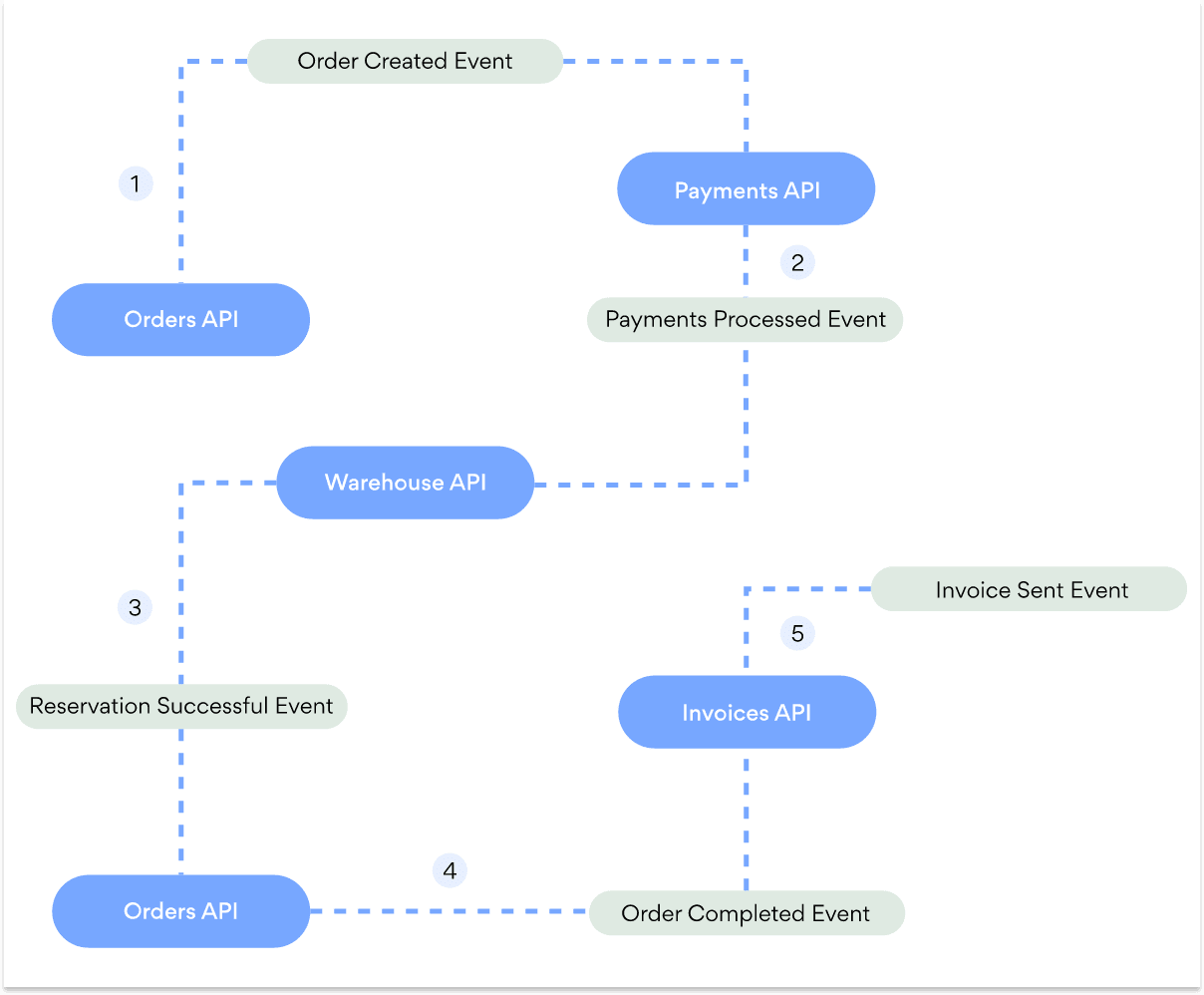
This method is best when there are more teams involved in the management of sagas. The benefit is that each team can work exclusively on sagas within their own scope.
Because there is no central coordinator, we don’t need a separate microservice responsible for coordinating a workflow. However, this could make it difficult to understand more complex workflows and how certain services are interrelated. Also, keep in mind that there could be a cyclic dependency between microservices.
Rollback in choreography
Since there is no centralized coordinator, corresponding microservices listen for failure events to be able to rollback.
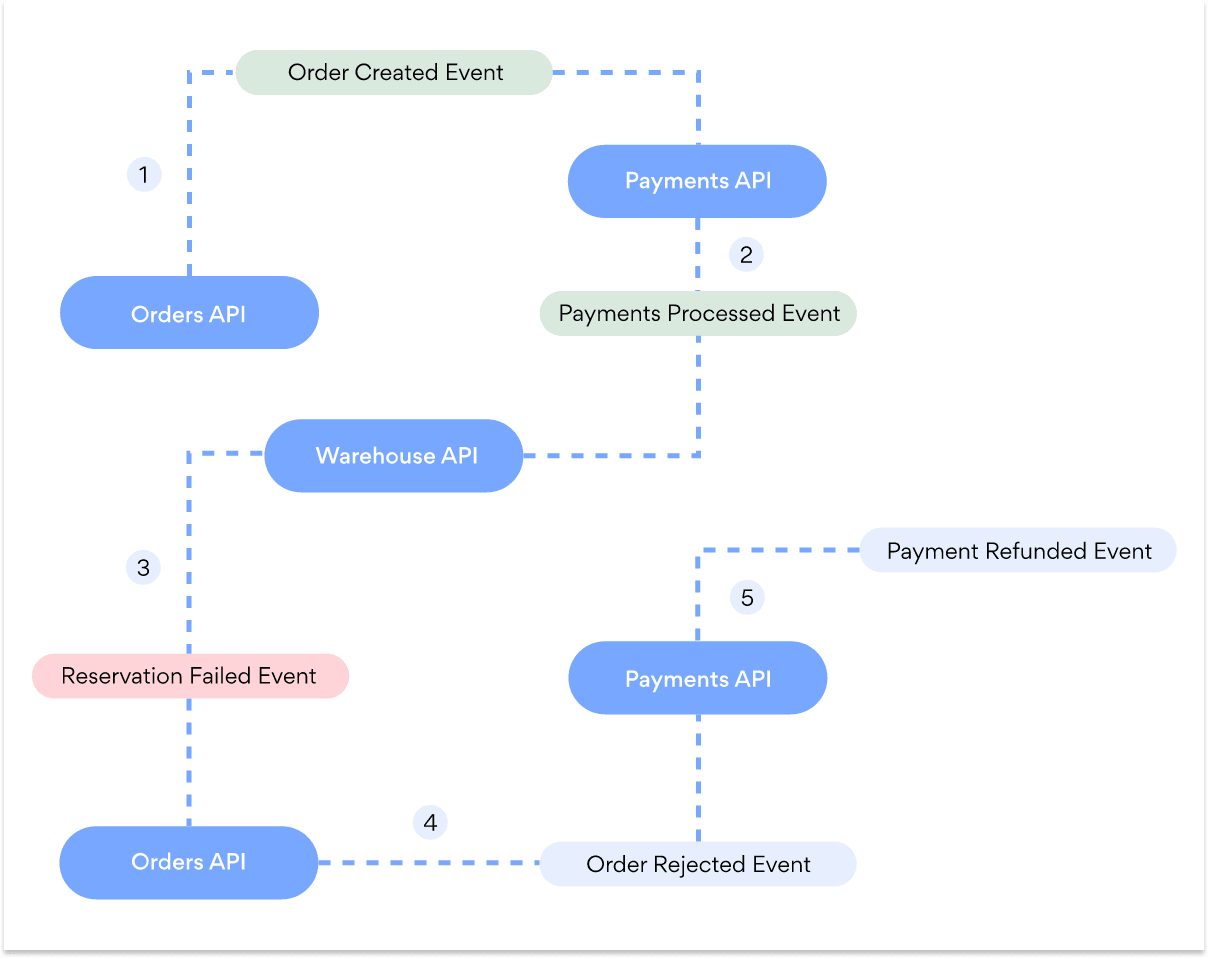
In the above diagram, the Warehouse API has failed to reserve a stock and publishes the corresponding “Reservation Failed” event. Other services then respond to this event - the Orders API rejects the order and the Payments API refunds the payment.
Mixing styles
Even though these two types of saga are very different, they can be mixed together. We can have order creation workflows when one saga has an orchestrator but one of the transactions (for example, reserving the stock) could be choreographed.
Other saga tips
Global transaction IDs: It’s a good idea to give sagas global transaction IDs. They can help with monitoring or debugging, but sharing the global transaction ID across all events lets you identify which transaction failed and to take the appropriate actions.
Semantic locks: When using the saga mechanism on each step, changes are committed to separate microservices. The saga philosophy doesn’t let us use real locking, which can lead to data inconsistency while the saga is still in progress.
You can include temporary state values to prevent other transactions from changing the wrong values. Let’s use the PENDING status to indicate that an order is in process. Now we can prevent cancelling the order if its status is PENDING, and other microservices will be able to read the PENDING state as well.
This means that we need to pay special attention to cases in which the ACID isolation property may not be fulfilled and ensure that we maintain it.Idempotency: Idempotent actions help avoid problems when the same request is sent twice, especially for compensation transactions when rollbacks are in progress.
Returning the response: Sagas can sometimes encompass many transactions that can take a while to be completed. This raises the question: should we return responses after all those transactions are completed or make their jobs asynchronous?
For longer sagas, it can become vital to return responses instantly and process the saga transactions asynchronously. I highly recommend this approach. It follows the best practices for rest APIs. Ensure that all requests are small and quickly executed.
In these cases we usually return http status 202, which means “accepted.” The client can then check the result using the corresponding endpoint or should be notified by the API service that the saga has been executed.
Summary
We have looked at several ways to implement the saga pattern and its pros and cons.
In general, if you need rollback processes with transaction compensation or you’re dealing with long-lived transactions, sagas are a good or even your best option.
Even though the saga pattern introduces greater complexity, it is preferable when you need to manage data consistency between microservices without tight coupling.