How we scale continuous deployment with GitLab runners
Alan Vezhbitskis
April 15, 2021
Software developers need stable tech and infrastructure to establish the best possible deployment processes. The same was true for NordVPN – we needed technology that would allow us to implement Continuous Integration and Continuous Delivery, or CI/CD. We needed something that would enable us to build, test, and regularly release software with maximum efficiency.


To meet these needs, we use GitLab Runners. We’ll delve into our joint evolution with GitLab Runners, including what we tried, learned, and have now.
GitLab and GitLab Runners
GitLab tracks changes in multiple files and coordinates workloads across the entire software development and application life cycle. We use GitLab for software development because of the large amount of variables needed to keep up with the CI/CD process. GitLab allows multiple developers to work on the same code, constantly implementing new changes. It creates a cohesive, regular, and efficient workflow. Our positive past experiences with it and the integration opportunities all added up to make this a logical and convenient choice for us.
Now, what is a GitLab Runner? It’s an application that works together with GitLab CI/CD to run similar jobs in a pipeline. A pipeline is a collection of automated actions that allow software engineers to easily build and deploy code to new platforms. When jobs are in a pipeline, it allows a developer to implement and process multiple instructions at the same time. Pipelines are a top-level component that are a necessity for CI/CD.


GitLab and NordVPN
Most projects begin with manual deployment code versioning servers. Although – the first real baby steps are probably deployment directly from the developer’s computer to the production server, but that doesn’t apply to NordVPN – we were born running!
In the beginning, NordVPN only had a few code deployments per week. Our development infrastructure was quite simple – a GitLab server and a few GitLab Runners were enough.
As we grew, the technological needs were desperate for an expansion. Our demand grew from a few deployments a week to at least 100 deployments per day in our normal flow, with 5-10 parallel deployments for different applications or to different environments. And that was for only one part of our product.
Using our existing Gitlab Runners, we built Documentation, RPM and DEB packages, Docker images, and many other daily tasks. The GitLab Runners were paramount to our success.
Growth 1: More power
Our first big problem was the need to support different types of servers and their workloads. Different jobs required different servers, and they all had to run quickly enough to be able to keep up with the CI/CD process. We acquired a load of new physical servers for development, but some would spend time overloaded while others were chilling. We also still experienced the usual network and hardware issues that usually come packaged with DevOps.


Growth 2: Hello, Docker
Moving our GitLab runners to Docker solved our server type problems. Docker-in-Docker is capable of covering almost every normal development process situation. This made the process of creating, deploying, and running software much easier by collecting every piece of data needed in a container.
However, Docker came with its own problems. Not only was it quite buggy, but traffic was now an issue that we hadn't had before, and the Docker cache on disk could not be cleared. The constant additions of new servers, including the introduction of cloud provider servers, also presented a new problem: IP address management.


Growth 3: Welcome to the cloud
Moving all GitLab Runners to the cloud helped solve the IP management issue. On top of this, entire NATs and networks were dedicated to the GitLab Runners, helping to solve the IP management and some traffic issues. Nonetheless, the Docker cache and overloading servers were still a problem.

Growth 4: Moving forward
Gen 1
Fortunately, this issue was solved with a simple workaround. We implemented our first-generation GitLab Runners with Docker Machine. This solved the Docker cache issue and, as a happy side-effect, solved the overloaded server issue as well. Multi-regional infrastructure was now easy to implement.


Gen 2
Next, we addressed our first-generation issues. In Gen 1, we used “preemptible” or “spot” instances, a cheap method to speed up certain jobs. Those instances, however, had a habit of dying at crucial moments. So, our first step for Gen 2 was to make it as stable as possible, which we did by resorting to much steadier regular instances.
Another challenge arose in the form of Docker Hub, which introduced additional limitations. This prompted us to build our own dedicated Docker image cache servers. We also introduced auto-scaling, which was entirely dependent on the time and day of the week. It ensured that as few servers as possible per region ever spent any time waiting for jobs, allowing us to maintain steady and strong performance. Furthermore, we configured it to destroy each server after one hour or 10 executed jobs.
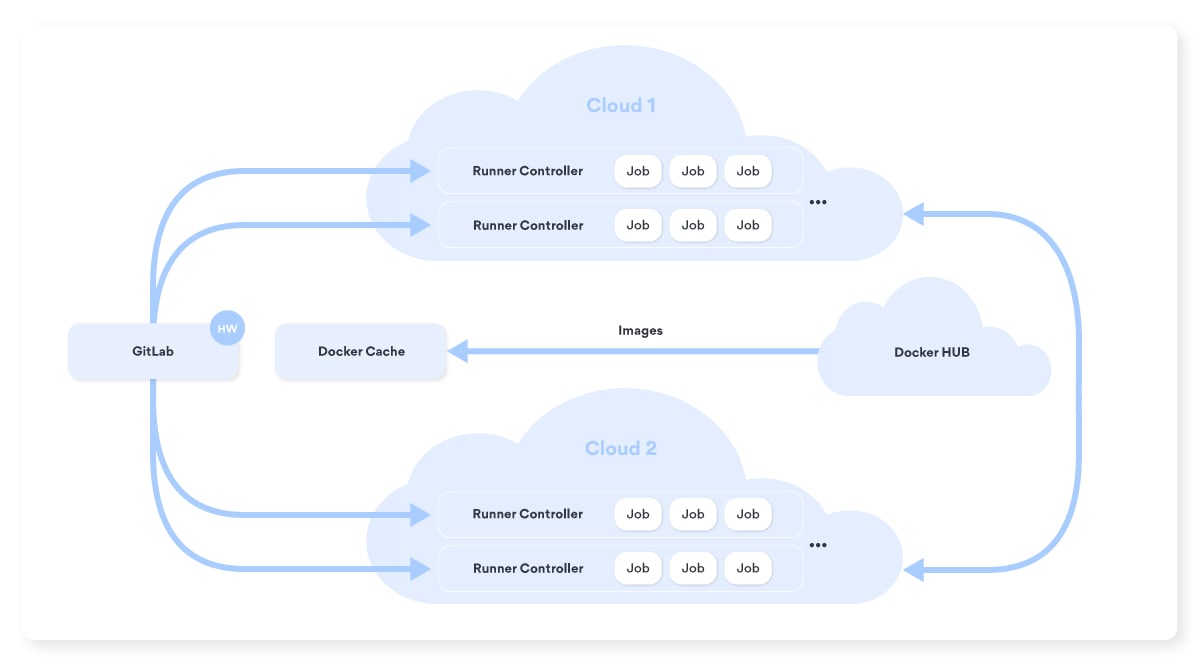
So what do we have now?
At the end of all this, what we are left with is two Docker Machine Runner Controllers for each region. They’re each directly registered in GitLab as GitLab Runners. Each Docker Machine controller is responsible for its own Docker pool. Developers in CI/CD simply need to set tags for specific applications or specific regions where their jobs should be executed.

What's next?
The only issue we have left to address is latency dips between regions. We will probably need to set up a Docker Image Content delivery network, but that is for the future.